
Reading time: 10 – 15 minutes
For many people, myself definitely included, the most difficult part of learning a new language is the vocabulary. There’s just always so much of it and, unlike grammar, I find it hard to condense down into learnable bites. The world is full of things, so language is full of words to describe them.
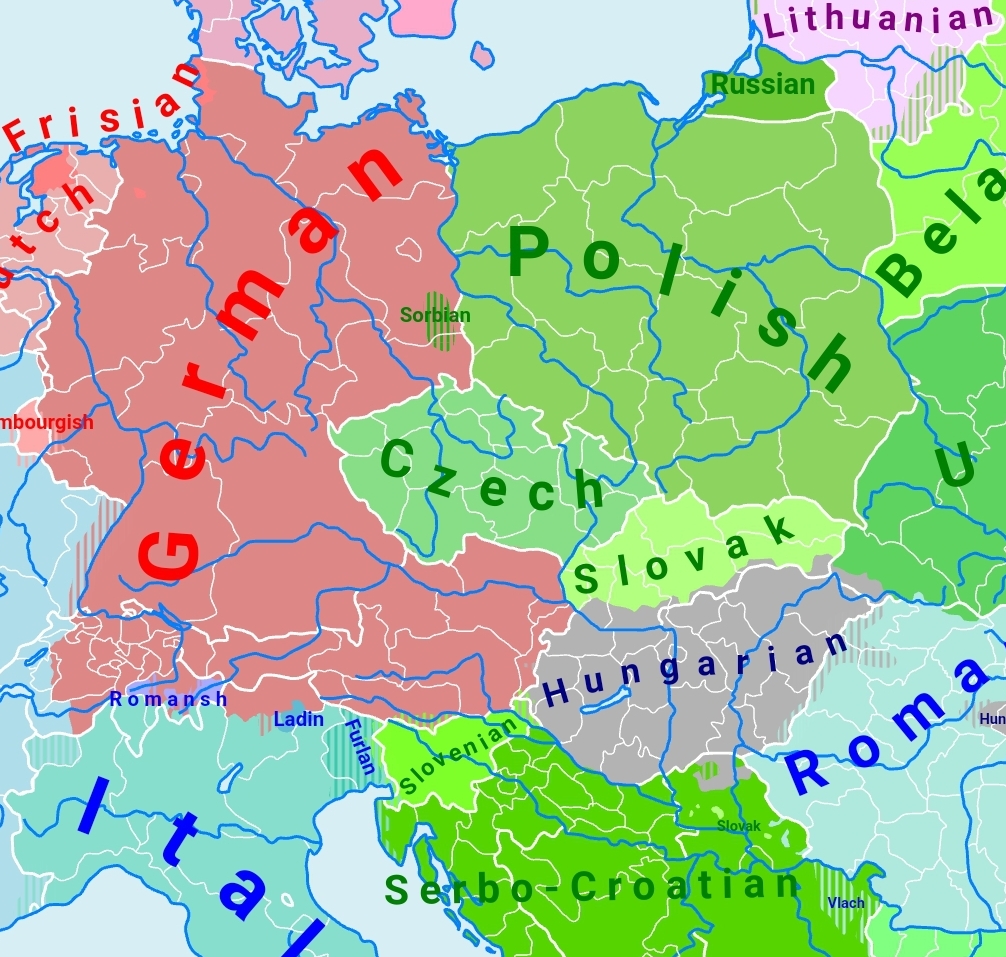
As always, vocabulary tends to be easier when you’re learning a ‘neighbour’ of a language you already know, such as your mother tongue. For an English speaker, French and German are like neighbours – geographical, historical, cultural and linguistic neighbours. These languages have much in common with English, and the similarities are a welcome aid for learners.
German’s own linguistic neighbour to its east (and north and south) is Czech. This one degree of separation from English has consequences for native English speakers who want to learn a bit of Bohemian. As a member of the Slavic language family, the lexicon of Czech (the Czexicon?) can look scarily unfamiliar. One friend confessed to me that she didn’t recognise a single word until the eighth lesson of Duolingo. This makes the language hard for Anglophone leaners to remember and therefore to achieve fluency in.
While Part I dealt with a problematic sound, this second instalment of Cheat Your Way to Czech is my small contribution to overcoming the lexical challenge. There are all kinds of techniques that people have come up with to help with vocab learning (mnemonics, charts, etc.), but I’ll leave those to an actual Czech teacher. What I can help with is etymology.
We learners can make use of the many journeys that words take across languages and time. That is to say, we can exploit the etymological links between English and Czech to make words more familiar. Believe me, there are plenty of links! The post is divided up into three parts, to reflect the three general ways in which the two languages might have such word connections: inheritance, borrowing and calquing.
While, as the title suggests, this post is intended for anyone who might be learning or want to learn Czech, I’m confident that it can also offer some good nuggets of knowledge for all linguistically inclined people, be they Czech enthusiasts or not!
Type I: Inheritance
While Czech belongs to the Slavic family of related languages, it also belongs to the wider Indo-European family. These many languages trace their history back to a single, prehistoric ancestor – and English is another member of the family too. What this means is that some Czech and English words are cousins, or rather cognates, which the two languages have inherited from that common origin.
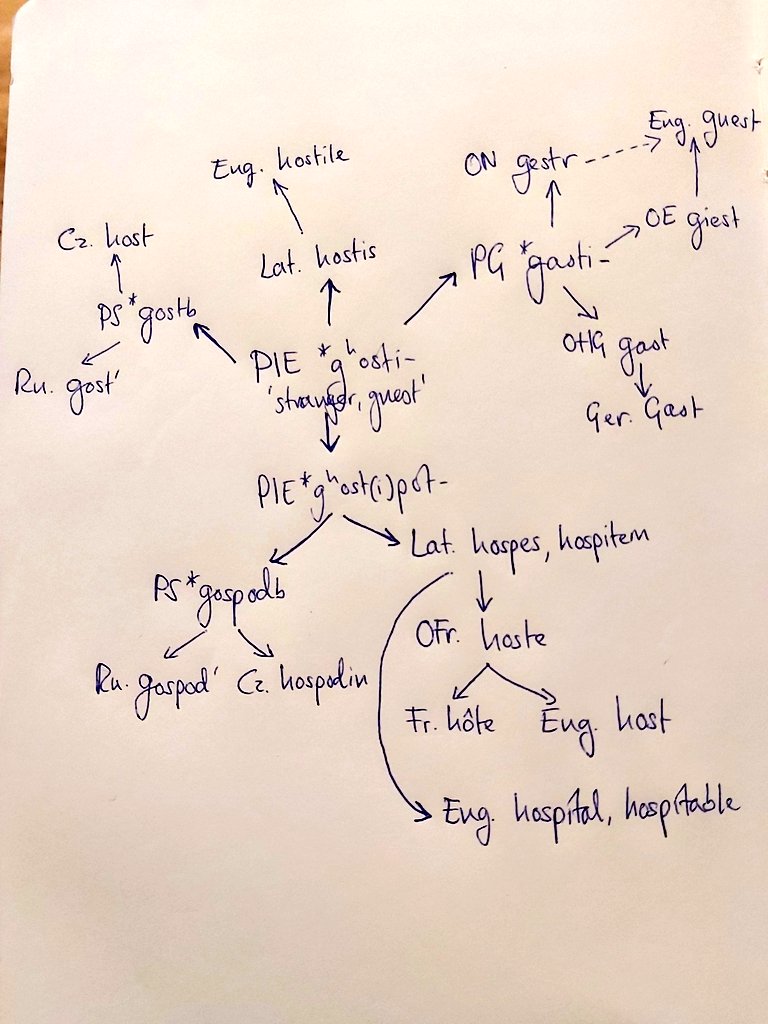
So many connections are there for the taking, though admittedly some Czech-English pairs look more alike than others. While Czech nos and English nose are comfortably similar, oko and eye are no less related. So too are plíce ‘lung’ and Latin pulmō, from which English gets pulmonary. Czech žena is not related to English woman, but it can be connected to queen, and also to Ancient Greek gunḗ, from which English gets gynaecology. Guest is cognate with its Czech equivalent host, as is English’s own word host, though via a different route.
Honestly, there’s no predicting what kind of word might have an English cousin; a particularly delightful surprise revelation for me was learning that the Czech word for beaver is bobr, a cognate.
That being said, numbers are good candidates for related words. Dva and two look similar, especially if we were still to pronounce the W in two. Tři and three look and sound even more alike, while šest and sedm are fairly similar to six and seven. The Czech numbers osm and deset don’t share much with eight and ten, but they do look like their well-known Latin counterparts, octō and decem, with both numbers displaying a correspondence of Latin C to Czech S (octō, decem = osm, deset).
Sound correspondences like this are extremely important in the field of historical linguistics. When two languages display a regular correspondence between two sounds across their vocabularies, we can propose a rule and a theory that explain how it came to be. Typically, the explanation is that the sounds come from a common origin, but have since diverged, so they’re no longer the same.
Take three more examples of the correspondence between Latin C and Czech S. Czech has the words srdce, sto and srnec, meaning ‘heart’, ‘hundred’ and ‘male roe deer’. Latin has the words cor (genitive singular: cordis), centum and cornū, meaning ‘heart’, ‘hundred’ and ‘horn’. For identifying cognates, these three pairs feel like a good fit. Their forms and meanings mostly match each other, more so if we explain srnec as a ‘horned thing’.

What’s more, their translations into English display another regular correspondence: the English words look similar, except that they begin with H. They too are cousins. While linguists have gone on to flesh out the details, explaining how, when and why it came be, ‘Czech S = Latin C = English H‘ is a simple rule of sound correspondences that can help us learners to appreciate how some Czech words are more familiar than we first think.
- srdce = cor = heart
- sto = centum = hundred
- srnec = cornū = horn
- sršeň = crābrō = hornet
It’s all thanks to the languages’ common ancestry. In this particle example, it’s Latin that most likely maintains the original sound of the three, or close to it.
Correspondences aren’t neat though. Sometimes, one sound in one language can correspond to two in another, which is usually determined by the contexts in which the sounds appear. For instance, Czech Z may match up to English K/C.
- znát = know
- lízat = lick
- zrno = corn
But it could also match up to G, as in the cognates zlato and gold. As messy and unbelievable as this all seems at first glance, it has been worked out how the different correspondences work and therefore how to predict them in particular words, but that’s another story.
All this is to say that the cognates and correspondences are out there for you to use. While you don’t have to learn all the correspondences and sound laws (they are intricate), if you’re struggling to remember a particular word, it could help to look up where it ultimately comes from (Wiktionary is a good start place to start). You may be surprised by how familiar its English cousin is!
Type II: Borrowings
Another way that Czech and English have cognates is borrowing. This stands in contrast with inheritance; while inherited words go back to an ancient time when the two languages were one, loanwords are those that have since entered Czech from an outside source, and may themselves have their own connection to English.
Loanwords have had a much less prominent effect on the modern Czech language when compared with English. This is in large part due to the National Revival of the 19th century, which aimed to promote all things Czech against the dominant German language of the Austro-Hungarian Empire. This meant that German loanwords were to be eschewed by patriots in favour of Bohemianisms and Moravianisms.
Nonetheless, many loanwords have survived and thrived in the language. Some arrived long ago and now are completely assimilated. For instance, that Czech-est of delicacies, the dumpling, is widely known as a knedlík – a word that comes German Knödel. Jan Hus himself even included it among his list of hated Germanisms in the early 15th century.

Other words are more recent entrants into the lexicon, and so tend to reflect something of their origin in their spelling. As one of today’s global languages, English has contributed much to modern Czech, such as words like meeting, leader and business. Though some people object to it, their naturalised status within the language has even led to their spelling as mítink, lídr and byznys.
As a general rule, the longer a loanword has existed within a language, the greater the chances of its assimilation in sound and spelling. While the English loanwords tend to be newer and therefore more obvious, words borrowed from prestigious languages of the past tend not to be so apparent. Religious terms, for example, borrowed from Latin and Greek many centuries ago, include words like biskup, kostel and mše (‘bishop’, ‘church’, ‘mass’), which have diverged in form and even meaning from Latin episcopus, castellum and missa. Likewise, the Czech words for ‘vinegar’ and ‘chalk’, ocet and křída, aren’t too much like their Latin ancestors acētum and crēta, from which English gets acetic and cretaceous.
Czech and German (or rather, all the languages that come under ‘German’) have been in contact for over a millennium. An early borrowing has led to the important Czech verb děkovat ‘to thank’, the ancestor of which survives in German as danken. Both are related to English thank. German also supplied Czech with the words ksicht ‘face’ and knajpa ‘pub’, which have more negative connotations compared with the original Gesicht and Kneipe. And where would Czech be without the buřt sausage, coming from German Wurst?
Furthermore, some words are more like ‘half borrowings’ – part borrowed, part native. Czech hřbitov ‘cemetery’ has its origins in German Friedhof, but with an influence from the root of the verb pohřbít ‘to bury’.

Simply put, much of the Czech lexicon originates in other languages – it just may not be obvious. Especially if you know some German, these loanwords can be a great help!
Part III: Calques
Strictly speaking, a calque is a type of borrowing, but with a difference. Calquing occurs when a language borrows the meaning and structure of a foreign word, but translates it part for part. ‘Loan translation’ is another term for this process. For instance, German has the words Kindergarten and Biergarten. While English has simply borrowed the first outright, English has calqued the second, keeping its sense but translating its component parts, forming the compound noun beer garden. Likewise, the word loanword is a literal translation of German Lehnwort, rather than a simple borrowing. Since calque was borrowed from French, this means that, ironically, loanword is a calque, while calque is a loanword.
However, a word of scientific caution: calques on their own give us little indication of their language of origin. If two languages in contact display words that match each other in meaning and formation, it’s reasonable to say that it’s not a coincidence and that calquing has taken place – but, unlike with straightforward borrowing, they give us much less of a clue about which word inspired the other, or when it happened. It’s historical circumstances and the written record that allow us to make the call about parallel formations between words.
Calquing has been particularly important in the development of modern Czech, because it offers a means of nativizing loanwords. If a language likes and wants to use a word from another language, but, for political reasons, doesn’t want to simply take that language’s vocabulary, a loan translation is the optimal solution. It’s a way of making foreign words one’s own.
Calques are another way in which the Czech lexicon is much more familiar than appearances seem. Take, for instance, the word počítač, a word I personally struggled to remember. It means ‘computer’ and it helped me to realise that, like English computer, the word comes from a verb for ‘to count’ (počítat), itself related to the noun for ‘number’, číslo.
Similarly, you might know the basic Czech adjective tvrdý, which means ‘hard’ or ‘firm’. Just as English has the verb confirm, Czech has potvrdit, which has tvrdý as its root. English insurance is visibly built on the adjective sure, and so if you know jistý ‘sure’, you can have a good guess at pojištění, a word that we foreigners in the Czech Republic need to know.
My own knowledge of German has been particularly useful for making sense of Czech vocabulary. For instance, the two parts of představit (před–stavit) match up to those of German vorstellen, and like the German verb, představit can mean both ‘introduce’ and ‘imagine’. Hence, a calqued origin for one of the two seems a reasonable idea. Even if it is not the case, their parallel formation can come in handy for learners regardless.
Likewise, German and Czech both distinguish between ‘going on foot’ and ‘going by vehicle’. German has the verbs gehen and fahren, and Czech has jít/chodit and jet. Both languages also build on this distinction for their words for ‘entrance’ and ‘exit’. German pedestrians exit via an Ausgang, but German vehicles via an Ausfahrt. Likewise, Czech uses východ for people and výjezd for cars on the road. Again, while it isn’t certain that calquing has taken place, I’ve appreciated and made use of the similar formations.
The Czech verb psát means ‘to write’ and as such translates to scrībere in Latin and gráphein in Ancient Greek. Because of these equivalences, Czech uses this root in its words for manuscript and geography: rukopis (literally ‘hand-writing’) and zeměpis (‘earth-writing’).

Various languages in Europe take their word for ‘please’ from their verb for ‘to ask’ or ‘to request’. In Czech, prosím ‘please’ comes from the first-person singular form of prosit. German developed its word in the same way; bitte comes from a form of bitten. Since other languages in the region show the same thing, this calquing seems to be an areal phenomenon.
Just as there are partial loanwords, there can also be partial calques. German Weihnachten, meaning ‘Christmas’, is a compound of words for ‘holy’ and ‘nights’. Czech has partly directly borrowed and partly calqued this with its word Vánoce, translating German Nacht with Czech noc.

For me, calques have been by far the most useful way to unravel Czech vocabulary. While calques are in theory the least obvious of foreign influences on Czech, they are numerous. So, if a word or even a phrase is giving you grief, it’s worth picking it apart and looking at its components – German, Russian, Latin, even English may have a similar construction, and there may be a historical reason why that is.
To Conclude
This is just the smallest of introductions to the etymological connections between English and Czech. The thing to bear in mind is that Czech isn’t ‘just a Slavic language’; it’s a living thing, existing alongside and cooperating with other languages, sensitive to the circumstances of its world. The Czech lexicon is therefore not monolithic and it’s not an unsurmountable mountain. It’s more like a lush forest, in which, despite first appearances, there is plenty of order, the borders are not definite and you can recognise more than you think.
The long and short of it is that if you’re learning Czech, etymology is definitely your friend! Look for the connections – they can be of various types, and often not very obvious, but they are there.

This only scratches the surface and makes some tenuous claims, which are not backed up in academic literature in English or Czech.
This article demonstrates why you’re struggling to learn vocabulary in a Slavonic language – all Slavonic languages build vocabulary in a very systematic way and once the system is learnt you will progress much faster.
Czech is not a particularly difficult language for English speakers to learn: the biggest challenge is the gulf between the written and spoken language.
Good luck!
LikeLike
Dear Jan. Allow me to address the points in your comment, as I feel that some are due to misunderstanding, which it could be beneficial to resolve.
– The post is intended as an accessible introduction, so it only naturally scratches the surface.
– I believe I can provide sound academic references for all claims made in this post. I myself am a doctoral student and all my work is grounded in academic scholarship.
– I never said that I am struggling to learn vocabulary in a Slavic language. While I do say that I personally find remembering vocabulary the most difficult in any new language, I reckon my progress in Czech is fine. Native Czechs says my Czech is good.
– Of course Slavic languages build vocabulary systematically. This post doesn’t deny that, but it also isn’t its point. The point is to find connections to English, not to analyse native Slavic systems.
– I can categorically state that Czech is difficult for English speakers to learn, much more so than German or French. I know a great many Anglophone learners and the challenge of Czech is a common topic of conversation. The gulf between written Czech and spoken Czech is really not so serious for learners – it’s a matter of some different endings and specific vocabulary. It’s not nearly as serious as many Czechs believe.
Thank you for the wishes of good luck.
LikeLike